

เมื่อโครงข่ายอินเทอร์เน็ตยุคใหม่ผูกชีวิตเราไว้กับชื่อเดียวอย่าง Cloudflare แค่สะดุดแค่ 20–30 นาที โลกทั้งใบเหมือน “เน็ตล่มพร้อมกัน” ทั้ง LinkedIn, Zoom, Coinbase, Canva, Substack, Shopify, Deliveroo ไปจนถึงเว็บข่าวและอีคอมเมิร์ซอีกเพียบ ต้องขึ้นหน้าเออร์เรอร์พร้อมกันแบบคนใช้เน็ตมองหน้ากันงง ๆ ว่า “คราวนี้ใครพัง?” ก่อนจะพบว่าต้นเหตุคือ Cloudflare เจ้าเก่าเจ้าเดิมนี่แหละ
บ้านกีฬาเลยขอพาไปไล่เรียงแบบย่อยง่ายแต่เนื้อหาแน่น ว่า Cloudflare คือใคร? ทำไมล่มทีโลกสั่น? แล้วเหตุขัดข้องล่าสุดวันที่ 5 ธันวาคม 2568 เกิดอะไรขึ้น ทำไมถึงกลายเป็นอีกหนึ่งเคสใหญ่ในประวัติศาสตร์อินเทอร์เน็ต พร้อมบทเรียนสำคัญที่คนทำเว็บยุคนี้ – โดยเฉพาะเว็บไซต์กีฬา ข่าว และคอนเทนต์แบบเรา ๆ – หนีไม่พ้นต้องคิดใหม่เรื่อง “แผนสำรอง” กันจริงจัง

Cloudflare คือใคร? ทำไมล่มทีเหมือนเน็ตทั้งโลกหายไป
Cloudflare ไม่ใช่แค่ “โฮสต์เว็บ” แต่คือ โครงสร้างพื้นฐานของอินเทอร์เน็ตยุคใหม่ หรือที่เขาเรียกกันว่า connectivity cloud – แพลตฟอร์มที่ช่วยเชื่อมต่อ ปกป้อง และเร่งความเร็วให้กับเว็บ แอป และบริการออนไลน์ทั่วโลก
- Cloudflare ทำตัวเป็น CDN (Content Delivery Network) กระจายข้อมูลไปเก็บไว้ในดาต้าเซ็นเตอร์ใกล้ผู้ใช้ ทำให้เว็บโหลดไวขึ้น
- เป็น Reverse Proxy คั่นกลางระหว่างคนเข้าเว็บกับเซิร์ฟเวอร์จริง ช่วยกรองทราฟฟิก ดูดซับการโจมตี ก่อนส่งคำขอที่ “สะอาด” ไปยังต้นทาง
- มี Web Application Firewall (WAF), DDoS Protection, Bot Management, DNS, SSL/TLS, Load Balancing ครบเซ็ตในแพลตฟอร์มเดียว
ปัจจุบัน Cloudflare ระบุว่าตัวเอง
- รองรับทราฟฟิกเว็บประมาณ 20% ของทั้งอินเทอร์เน็ต หรือพูดง่าย ๆ คือเว็บบนโลกกว่า 1 ใน 5 มี Cloudflare อยู่เบื้องหลัง
- มีดาต้าเซ็นเตอร์มากกว่า 330 เมือง ในกว่า 120–125 ประเทศ และให้บริการทราฟฟิกระดับเฉลี่ย หลายสิบล้าน HTTP requests ต่อวินาที ทั่วโลก
- บล็อกการโจมตีระดับ หลักร้อยพันล้านคำขอต่อวัน จากมัลแวร์ บอต และทราฟฟิกมุ่งร้ายรูปแบบต่าง ๆ
เพราะฉะนั้น ถ้าวันไหน Cloudflare “จามแรง ๆ” เว็บทั่วโลกก็พร้อมกัน “เป็นหวัด” ไปด้วย นี่คือภาพที่เราเห็นชัดมากในเหตุล่มรอบนี้
ดราม่า 5 ธันวาคม 2568 – 25 นาทีที่โลกทั้งใบสะดุ้ง
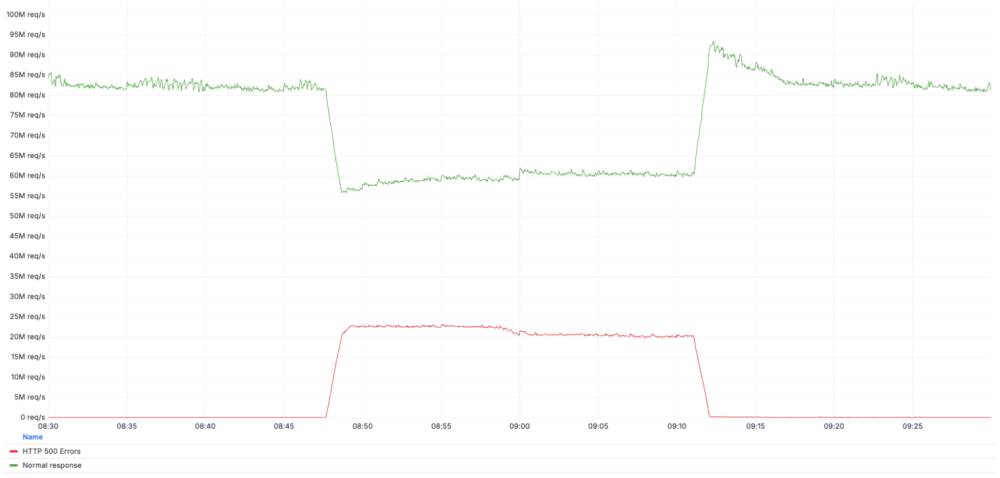
เวลา 08:47 น. UTC (ประมาณบ่ายแก่ ๆ ตามเวลาไทย) ของวันที่ 5 ธันวาคม 2568 Cloudflare รายงานว่าเครือข่ายส่วนหนึ่งเริ่มล้มเหลว ให้บริการเป็น HTTP 500 Error จำนวนมาก เหมือนเซิร์ฟเวอร์ “รับไม่ไหว” และตอบกลับด้วยข้อความผิดพลาด แทนคอนเทนต์ปกติ
จุดเด่นของเหตุการณ์นี้คือ
- เหตุขัดข้องกินเวลาประมาณ 25 นาที ก่อนจะรีบแก้ไขและคืนระบบได้ในเวลา 09:12 UTC
- Cloudflare ยืนยันว่า ไม่ใช่การโจมตีไซเบอร์ แต่เป็นปัญหาจากการเปลี่ยนแปลงการตั้งค่า/โค้ดภายในเอง
- คาดว่ามีทราฟฟิกประมาณ 28% ของ HTTP ทั้งหมดที่ผ่าน Cloudflare ได้รับผลกระทบ หรือพูดง่าย ๆ คือผู้ใช้จำนวนมหาศาลทั่วโลกเจอหน้าเออร์เรอร์ไปพร้อมกัน
ผลกระทบที่เห็นชัด ๆ จากรายงานหลายสำนักทั่วโลก ได้แก่
- เว็บใหญ่อย่าง LinkedIn, Zoom, Canva, Coinbase, Substack, Shopify, Deliveroo, HSBC และอีกมากมาย มีผู้ใช้แจ้งปัญหาพร้อมกันใน Downdetector ว่าเข้าไม่ได้ หรือโหลดไม่ขึ้น
- หุ้น Cloudflare ในตลาดสหรัฐฯ ร่วงลงชั่วคราวถึงราว ๆ 4–4.5% ก่อนจะเด้งกลับบางส่วน หลังบริษัทประกาศว่าแก้ไขปัญหาได้แล้ว
ที่น่าจับตาคือ นี่ไม่ใช่ครั้งแรกในรอบเดือนที่ Cloudflare ทำให้ “เน็ตทั้งโลกสะเทือน”

ต้นตอจริง ๆ คืออะไร? เมื่อเกราะป้องกันกลายเป็นต้นเหตุ
ในบล็อกโพสต์ทางการของ Cloudflare ระบุชัดว่า ต้นเหตุของการล่มรอบนี้มาจาก การเปลี่ยนแปลงการทำงานของ WAF (Web Application Firewall) เพื่อป้องกันช่องโหว่รุนแรงระดับสูงใน React Server Components – CVE-2025-55182 ซึ่งถูกประเมินความรุนแรงระดับ CVSS 10.0 (เต็ม 10)
ภาพรวมแบบย่อยง่ายคือ
- วงการเว็บทั่วโลกเพิ่งถูกแจ้งเตือนช่องโหว่ React Server Components
- ช่องโหว่นี้เปิดโอกาสให้ผู้ไม่หวังดีโจมตีแอปที่ใช้ React/Next.js ในฝั่งเซิร์ฟเวอร์ได้
- ผู้ให้บริการใหญ่ ๆ รวมถึง Cloudflare รีบออกมาตรการป้องกันให้ลูกค้า
- Cloudflare เลยปรับการทำงานของ WAF
- เพิ่มขนาด buffer ที่ใช้เก็บเนื้อหา request body จากเดิมประมาณ 128KB เป็น 1MB เพื่อวิเคราะห์ payload ได้ละเอียดขึ้น
- เป้าหมายคือป้องกัน payload แปลกปลอมที่อาจอาศัยช่องโหว่ React เข้ามาโจมตี
- ระหว่างปรับแต่ง Cloudflare ได้ ปิด “เครื่องมือทดสอบกฎ WAF ภายใน” ผ่านระบบ configuration กลาง เพื่อไม่ให้รบกวนการปรับแต่งจริงบนระบบโปรดักชัน
- แต่ใน proxy รุ่นเก่า (ที่ Cloudflare เรียกว่า FL1) มี บั๊กฝังอยู่ในโค้ดมานาน พอเจอกรณีที่ “ปิดการทำงานของกฎ execute บางตัว” ระบบกลับไปเรียกใช้ตัวแปรที่ไม่มีอยู่จริง (nil) ใน Lua ทำให้เกิด runtime error แล้วตอบกลับด้วย HTTP 500 ทันที
แปลเป็นภาษาคนง่าย ๆ คือ
Cloudflare พยายามอัปเกรดเกราะป้องกัน (WAF) เพื่อกันช่องโหว่ React แต่ระหว่างปิดสวิตช์เครื่องมือทดสอบเก่า ๆ ดันไปเตะ “บั๊กที่ซ่อนมานานหลายปี” จนโค้ดล้มทั้งแถบ กลายเป็นว่ากำแพงที่ตั้งใจเสริมให้หนา กลับทำให้ไฟดับทั้งเมือง
จุดที่น่าสนใจคือ บั๊กนี้ ไม่มีใน proxy รุ่นใหม่ (FL2) ที่เขียนด้วยภาษา Rust เพราะระบบ type safety ช่วยกันเคสประเภทนี้ไว้ ทำให้ Cloudflareยืนยันว่า ในโค้ดรุ่นใหม่ไม่เกิดปัญหานี้ขึ้น
ทำไมเหตุล่มรอบนี้ถึงถูกจับตาหนัก? เพราะมัน “ไม่ใช่ครั้งแรกในเดือนเดียว”
ย้อนกลับไปแค่สองสัปดาห์ก่อนหน้า วันที่ 18 พฤศจิกายน 2568 Cloudflare เพิ่งเจอเหตุล่มครั้งใหญ่ที่กินเวลา หลายชั่วโมง
- ต้นเหตุคราวนั้นมาจากการเปลี่ยนแปลงการตั้งค่าฐานข้อมูลสำหรับ Bot Management ทำให้ไฟล์คอนฟิกที่ใช้กับ proxy มีขนาดเกินข้อจำกัดที่โค้ดรองรับ ส่งผลให้เกิด HTTP 5xx ทะลักทั่วโลก
- ช่วงที่โดนหนักสุดกินเวลาราว 3 ชั่วโมงกว่า มีบริการดังอย่าง X (Twitter เดิม), ChatGPT, Spotify, เกมออนไลน์หลายเกม ไปจนถึงเว็บข่าวและบริการจำนวนมากได้รับผลกระทบ
เมื่อเอาสองเหตุการณ์มาวางคู่กัน ภาพที่โลกออนไลน์เห็นคือ
- โครงสร้างพื้นฐานที่เคยถูกมองว่า “โคตรเสถียร” กลับสะดุด สองครั้งในรอบไม่ถึงเดือน
- สองครั้งก็เกิดจาก การเปลี่ยนแปลงภายใน (configuration / code change) ทั้งคู่ ไม่ใช่การโจมตี
- ทั้งสองครั้งโดนกลุ่มลูกค้าจำนวนมหาศาล เพราะ สถาปัตยกรรมยังปล่อยให้ “การเปลี่ยนแปลงจุดเดียว” ส่งผลกระทบระดับโครงข่ายทั้งหมด
นี่คือเหตุผลที่ทั้งนักลงทุน นักพัฒนา และเจ้าของเว็บทั่วโลกเริ่มตั้งคำถามว่า
“เราไปพึ่งโครงข่ายแค่เจ้าเดียวมากเกินไปหรือเปล่า?”
Cloudflare รับผิด – พร้อมโรดแมปอัปเกรดความทนทานของระบบ
หลังเหตุการณ์ล่มทั้งรอบ 18 พ.ย. และ 5 ธ.ค. Cloudflare ออกมายอมรับตรง ๆ ว่า เหตุการณ์แบบนี้ “ไม่อาจยอมรับได้” สำหรับโครงข่ายระดับโลก และประกาศชุดแผนงานใหญ่เพื่อยกระดับความทนทานของระบบ
ประเด็นสำคัญที่ Cloudflareสัญญาว่าจะทำ ได้แก่
- Enhanced Rollouts & Versioning
- ทำให้การเปลี่ยนแปลงคอนฟิกสำคัญ ๆ เช่น WAF rules, security data, global config มีระบบ rollout แบบค่อยเป็นค่อยไปเหมือนซอฟต์แวร์ ไม่ใช่กดครั้งเดียวส่งไปทั่วโลก
- มีระบบ health check และ rollback อัตโนมัติเมื่อเจอความผิดปกติ
- Streamlined “Break Glass” – ทางลัดหยุดเปลี่ยนแปลงให้ไวที่สุด
- สร้างช่องทางฉุกเฉินที่ไม่พึ่งระบบที่อาจพังไปแล้ว ให้สามารถหยุด/ย้อนการตั้งค่าที่ก่อปัญหาได้แม้บางส่วนของ control plane จะล่ม
- Fail-Open Error Handling
- แทนที่โค้ดจะเลือก “ล้มทั้งด่านแล้วตอบ 500” เมื่ออ่านคอนฟิกไม่ได้หรือค่าผิดพลาด ระบบใหม่จะเลือก “ปล่อยทราฟฟิกผ่านในโหมดปลอดภัย (fail-open)” หรือ fallback ไปยังสถานะที่เชื่อว่าดีกว่าให้เว็บทั้งโลกตายพร้อมกัน
- Lockdown การเปลี่ยนแปลงชั่วคราว
- หลังเหตุการณ์ 5 ธ.ค. Cloudflare ประกาศล็อกการเปลี่ยนแปลงที่มีความเสี่ยงสูงชั่วคราว เพื่อให้ทีมวิศวกรปรับระบบ mitigation และ rollback ให้พร้อมกว่านี้ก่อนจะเดินหน้าต่อ
พูดง่าย ๆ คือ ยักษ์ใหญ่เองก็ต้อง “เรียนบทเรียนเจ็บ ๆ” ว่าในโลกที่ตัวเองถือคีย์เชื่อมเว็บไว้ถึง 20% แค่กดเปลี่ยนอะไรผิดนิดเดียวก็ทำเน็ตทั้งโลกสะดุดได้
มองภาพใหญ่: Cloudflare สำคัญแค่ไหนในยุคเว็บเร็ว–เว็บปลอดภัย
ถึงจะมีดราม่าล่มถี่ในเดือนเดียว แต่ปฏิเสธไม่ได้ว่า Cloudflare คือหนึ่งในเสาหลักของอินเทอร์เน็ตยุคนี้
ประโยชน์หลัก ๆ ที่ทำให้เว็บทั่วโลก รวมถึงสื่อกีฬา / เว็บข่าว / แพลตฟอร์มคอนเทนต์เลือกใช้ Cloudflare คือ
- เว็บโหลดไวขึ้นแบบเห็นได้ชัด
- CDN ช่วยแคชรูป ไฮไลท์วิดีโอ ตารางคะแนน และคอนเทนต์ต่าง ๆ ไว้ใกล้ผู้ใช้ เช่น แฟนบอลไทยที่เปิดอ่านเว็บยุโรป แต่ได้คอนเทนต์จากดาต้าเซ็นเตอร์ที่ใกล้กว่าเซิร์ฟเวอร์จริง
- ความปลอดภัยเพิ่มขึ้นโดยไม่ต้องเป็นเซียนไซเบอร์
- WAF, DDoS Protection, Bot Management ช่วยกันบล็อกทราฟฟิกมุ่งร้าย ทั้งจากสแปมบอต บอทขูดคอนเทนต์ ไปจนถึงการยิง DDoS ใส่เว็บ
- SEO ดีขึ้นทางอ้อม
- เว็บโหลดไวขึ้น มี HTTPS, ปิดรูรั่วเล็ก ๆ น้อย ๆ ทำให้คะแนนคุณภาพเว็บในสายตาเสิร์ชเอนจินดีขึ้น โอกาสติดหน้าค้นหาดีกว่าเว็บช้า
ข้อมูลจาก Cloudflare ระบุว่าพวกเขา
- ให้บริการจากดาต้าเซ็นเตอร์มากกว่า 330 เมืองทั่วโลก ครอบคลุมกว่า 125 ประเทศ
- ประมวลผลทราฟฟิกระดับหลายสิบล้านคำขอต่อวินาที และบล็อกภัยคุกคามระดับหลักแสน–หลายร้อยพันล้านคำขอในแต่ละวัน
สำหรับคนทำเว็บ ไม่ว่าเว็บเล็กหรือเว็บใหญ่ การใช้ Cloudflare ก็แทบจะกลายเป็น “มาตรฐาน” ที่ช่วยให้เว็บดูดีขึ้นทั้งด้านความเร็วและความปลอดภัยโดยไม่ต้องลงทุนโครงสร้างพื้นฐานเองทั้งหมด
บทเรียนสำคัญสำหรับคนทำเว็บ: พึ่ง Cloudflare ได้ แต่ห้ามพึ่ง “เจ้าเดียว”
เหตุการณ์ล่มสองรอบล่าสุดของ Cloudflare เป็นสัญญาณดัง ๆ ว่า
“ไม่มีโครงข่ายไหนสมบูรณ์แบบ 100% แม้จะใหญ่แค่ไหนก็เถอะ”
สำหรับเจ้าของเว็บ ข่าวกีฬา เว็บสรุปผลแข่งขัน ไลฟ์สกอร์ รวมถึงแพลตฟอร์มคอนเทนต์ทุกสาย สิ่งที่ควรคิดต่อคือ
- อย่าพึ่งผู้ให้บริการรายเดียวแบบไม่มีแผนสำรอง
- ถ้าเว็บคุณ critical มากจริง ๆ อาจต้องคิดถึง multi-CDN / multi-cloud หรืออย่างน้อยมี route fallback เมื่อ provider หลักล่ม
- ออกแบบเว็บให้มี “โหมดเอาตัวรอด”
- แคชเพจสำคัญแบบ static
- มีหน้าแจ้งเตือนฉุกเฉิน (status page) แยกจากโครงสร้างหลัก
- ใช้ระบบแคชฝั่ง origin เสริมไว้เผื่อ provider ด้านหน้าเจอปัญหา
- ติดตาม status page และ social ของผู้ให้บริการอย่างใกล้ชิด
- Cloudflare, AWS, Google Cloud, รวมถึงโฮสต์ของคุณเอง มีเพจรายงานเหตุขัดข้องเสมอ
- พอรู้ว่าเป็นปัญหาระดับระบบ ไม่ใช่เว็บเราเอง ก็ช่วยลดความตื่นตระหนกและวางแผนสื่อสารกับผู้ใช้ได้ดีขึ้น
- สื่อสารกับคนอ่านให้ไวและตรงไปตรงมา
- สำหรับเว็บข่าว–เว็บกีฬา เมื่อเกิดเหตุล่มจากโครงสร้างพื้นฐาน ควรมีแชนแนลสำรอง (เช่น โซเชียล) คอยอัปเดตผู้ใช้ว่า “ปัญหาไม่ได้เกิดจากการถูกแฮ็กข้อมูลส่วนตัว แต่เป็นเหตุโครงข่ายขัดข้อง” จะช่วยรักษาความเชื่อมั่นของคนอ่านได้มาก
********************ใส่รูป******************
มุมมองสายเว็บกีฬา: Cloudflare คือ “กองหลังตัวหลัก” ที่ยังจำเป็นอยู่ดี
ในโลกของ เว็บข่าวกีฬาอย่าง บ้านกีฬา หรือเว็บไฮไลท์บอล ตารางคะแนน ถ่ายทอดสด และบทความวิเคราะห์ต่าง ๆ Cloudflare แปลออกมาเป็นประโยชน์ที่จับต้องได้แบบแฟนบอลรู้สึกจริง ๆ เช่น
- เวลา แมตช์ใหญ่ อย่างฟุตบอลโลก, ยูฟ่า แชมเปียนส์ลีก, ไทยลีก นัดชี้ชะตา ทราฟฟิกบนเว็บพุ่งแบบบ้าคลั่ง Cloudflare ช่วยดูดซับโหลดระดับนี้ได้ ดีกว่าปล่อยให้เซิร์ฟเวอร์ต้นทางรับเละคนเดียว
- ในยุคที่การโจมตีเว็บ รูปแบบสแปมคอมเมนต์ บอตยิงรีเควสต์ หรือยิง DDoS ใส่เว็บข่าว/เว็บพนัน/เว็บผลบอลสดเกิดขึ้นแทบทุกวัน การมี WAF และ DDoS Protection ติดอยู่หน้าบ้านถือเป็น “กองหลังตัวโหด” ที่ช่วยยืนบังด่านแรกให้เว็บรอด
- การแคชภาพ ไฮไลท์ และสถิติ ทำให้แฟนบอลเปิดบทความ, คลิปไฮไลท์, ตารางบอลวันนี้ ได้เร็วขึ้น แม้จะอยู่ต่างประเทศหรือเน็ตไม่เสถียรมาก
ดังนั้นแม้ Cloudflare จะมี “หลุดฟอร์ม” จนทำเน็ตสะดุดบ้าง แต่ด้วยสเกลและความสามารถในด้านความเร็ว–ความปลอดภัย มันก็ยังเป็น “ตัวจริง” ในระบบอินเทอร์เน็ตอยู่ดี เพียงแต่ทุกคนต้องเปลี่ยนมุมมองจาก “เชื่อใจแบบไม่เผื่อใจ” เป็น “ใช้ให้เต็มประโยชน์ แต่เตรียมแผนสำรองไว้เสมอ”
สรุป – เมื่อ Cloudflare สะดุด โลกทั้งใบต้องคิดใหม่เรื่องความเสี่ยงดิจิทัล
เหตุการณ์ Cloudflare ล่มวันที่ 5 ธันวาคม 2568 คืออีกหนึ่งหลักฐานชัด ๆ ว่า
- อินเทอร์เน็ตทุกวันนี้ รวมศูนย์อยู่กับผู้ให้บริการรายใหญ่ไม่กี่เจ้า
- ปัญหาครั้งนี้ไม่ได้มาจากแฮ็กเกอร์ แต่จาก “การเปลี่ยนโค้ด/คอนฟิกที่ผิดพลาด” ซึ่งเป็นความเสี่ยงที่เลี่ยงไม่ได้ในระบบซอฟต์แวร์ขนาดใหญ่
- ยิ่ง Cloudflare ขยายใหญ่ ปกป้องเว็บมากขึ้นเท่าไหร่ เวลา “สะดุด” ทีเดียว ผลกระทบยิ่งกว้างขึ้นเท่านั้น
สำหรับคนใช้เน็ตทั่วไป นี่อาจเป็นเพียงไม่กี่นาทีหรือชั่วโมงที่เว็บโปรดเข้าไม่ได้ แต่สำหรับเจ้าของเว็บ แบรนด์ ธุรกิจ และสื่อออนไลน์ นี่คือเสียงเตือนดัง ๆ ว่า
ถึงเวลาออกแบบระบบให้ “อยู่รอดได้แม้เสาหลักตัวใดตัวหนึ่งล้มชั่วคราว”
โลกดิจิทัลไม่มีวันกลับไปช้าและง่ายเหมือนเดิม เครือข่ายซับซ้อนขึ้น ภัยคุกคามมากขึ้น และความคาดหวังของผู้ใช้อยู่ในระดับ “ต้องออนไลน์ตลอดเวลา” ใครที่วางแผนรับมือความเสี่ยงตั้งแต่วันนี้ จะยืนได้มั่นคงกว่าในวันที่โครงข่ายยักษ์สะดุดอีกครั้งอย่างเลี่ยงไม่ได้
แฟนข่าวไอที–กีฬา–เศรษฐกิจดิจิทัลที่อยากตามทุกจังหวะของโลกออนไลน์ยุคใหม่ อย่าลืมติดตาม ข่าวเด่น ข่าววันนี้ ที่ ข่าวการค้นหาที่มาแรงบ้านกีฬา เราจะคอยอัปเดตทั้งเรื่องในสนามกีฬา และในสนามอินเทอร์เน็ตให้คุณไม่พลาดทุกจังหวะสำคัญ

